【強化学習#3】ベルマン方程式と動的計画法
記事の目的
youtubeの「【強化学習#3】ベルマン方程式と動的計画法」で解説した内容のコードです。
目次
1 環境とエージェント
import numpy as np import matplotlib.pyplot as plt import seaborn as sns np.random.seed(1)
class Environment:
def __init__(self, size=3, lucky=[]):
self.size = size
self.lucky = lucky
self.goal = (size-1, size-1)
self.states = [(x, y) for x in range(size) for y in range(size)]
self.value = {}
for s in self.states:
self.value[s] = 0
def next_state(self, s, a):
s_next = (s[0] + a[0], s[1] + a[1])
if s == self.goal:
return [(1, s)]
if s_next not in self.states:
return [(1, s)]
if s_next in self.lucky:
return [(0.8, self.goal), (0.2, s_next)]
return [(1, s_next)]
def reward(self, s, s_next):
if s == self.goal:
return 0
if s_next == self.goal:
return 1
return 0
class Agent():
def __init__(self, environment, policy=[0, 0, 1/2, 1/2]):
self.actions = [(-1, 0), (0, -1), (1, 0), (0, 1)]
self.environment = environment
self.policy = {}
for s in self.environment.states:
for i, a in enumerate(self.actions):
self.policy[(s, a)] = policy[i]
2 動的計画法
def value(agent, gamma=0.5, delta=0.001):
while True:
delta_max = 0
for s in agent.environment.states:
v_next = 0
for a in agent.actions:
for p, s_next in agent.environment.next_state(s, a):
r = agent.environment.reward(s, s_next)
v_next += agent.policy[s, a]*p*(r+gamma*agent.environment.value[s_next])
delta_max = max(delta_max, abs(agent.environment.value[s] - v_next))
agent.environment.value[s] = v_next
if delta_max < delta:
break
3 可視化用関数
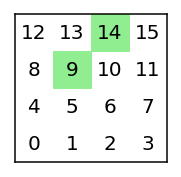
def show_maze(environment):
size = environment.size
fig = plt.figure(figsize=(3,3))
plt.plot([-0.5, -0.5], [-0.5, size-0.5], color='k')
plt.plot([-0.5, size-0.5], [size-0.5, size-0.5], color='k')
plt.plot([size-0.5, -0.5], [-0.5, -0.5], color='k')
plt.plot([size-0.5, size-0.5], [size-0.5, -0.5], color='k')
for i in range(size):
for j in range(size):
plt.text(i, j, "{}".format(i+size*j), size=20, ha="center", va="center")
if (i,j) in environment.lucky:
x = np.array([i-0.5,i-0.5,i+0.5,i+0.5])
y = np.array([j-0.5,j+0.5,j+0.5,j-0.5])
plt.fill(x,y, color="lightgreen")
plt.axis("off")
def show_values(agent):
fig = plt.figure(figsize=(3,3))
result = np.zeros([agent.environment.size, agent.environment.size])
for (x, y) in agent.environment.states:
result[y][x] = agent.environment.value[(x, y)]
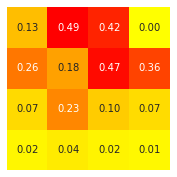
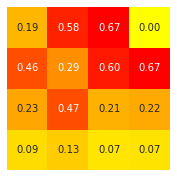
sns.heatmap(result, square=True, cbar=False, annot=True, fmt='3.2f', cmap='autumn_r').invert_yaxis()
plt.axis("off")
4 シミュレーション
4.1 シミュレーション1
env1 = Environment(lucky=[(1,2)]) agent1 = Agent(env1) show_maze(env1)

show_values(agent1)

value(agent1) show_values(agent1)
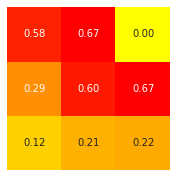
4.2 シミュレーション2
env2 = Environment(size=4, lucky=[(1,2), (2,3)]) agent2 = Agent(env2) show_maze(env2)
value(agent2) show_values(agent2)
4.3 シミュレーション3
env3 = Environment(size=4, lucky=[(1,2),(2,3)]) agent3 = Agent(env3, policy=[1/4, 1/4, 1/4,1/4]) show_maze(env3)
value(agent3) show_values(agent3)