
【pytorchで深層生成モデル#13】学習テクニックまとめ(DCGAN)
記事の目的
深層生成モデルのDCGAN(Deep Convolutional GAN)の実装を参考に、今までやってきた学習のテクニックのまとめを実装していきます。ここにある全てのコードは、コピペで再現することが可能です。
目次
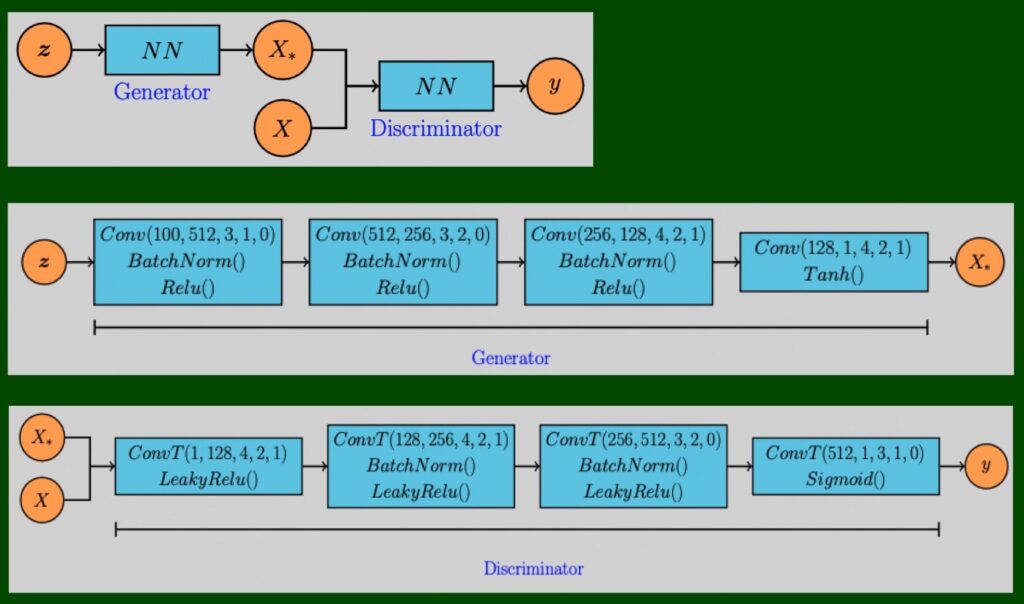
1 今回のモデル
2 準備




# [1]
!nvidia-smi
# [2]
# データ作成に使用するライブラリ
from torchvision import datasets
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
# モデル作成に使用するライブラリ
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
# よく使用するライブラリ
import matplotlib.pyplot as plt
import numpy as np
# 学習テクニックライブラリ
import torchsummary # モデルを確認するライブラリ
import pickle # モデルの保存と読み込みするライブラリ
import torchvision.utils as vutils # 画像データを保存するライブラリ
from torch.utils.data import Dataset # データセット作成に使用するライブラリ
from pathlib import Path # データセット作成に使用するライブラリ
from PIL import Image # データセット作成に使用するライブラリ
torch.manual_seed(1)
# [3]
batch_size = 100
n_channel = 100
n_epoch = 10
# [4]
!mkdir './data'
dataset = datasets.MNIST(root='.', download=True)
for idx, (img, _) in enumerate(dataset):
img.save('./data/{:05d}.jpg'.format(idx))
# [5]
!find /content/data/* -type f | wc -l
# [6]
class Image_dataset(Dataset):
def __init__(self, img_dir, transform=None):
self.img_paths = self._get_img_paths(img_dir)
self.transform = transform
def __getitem__(self, index):
path = self.img_paths[index]
img = Image.open(path)
if self.transform is not None:
img = self.transform(img)
return img
def _get_img_paths(self, img_dir):
img_dir = Path(img_dir)
img_paths = [p for p in img_dir.iterdir() if p.suffix in [".jpg", ".jpeg", ".png", ".bmp"]]
return img_paths
def __len__(self):
return len(self.img_paths)
# [7]
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
dataset = Image_dataset("/content/data", transform)
dataloader = DataLoader(dataset, batch_size=100)
# [8]
# データの読み込み
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device
# [9]
# Google ドライブにマウント
from google.colab import drive
drive.mount('/content/gdrive')
# [10]
%cd '/content/gdrive/MyDrive/'
# [11]
!mkdir './result_image'
!mkdir './result_model'
3 モデル



# [12]
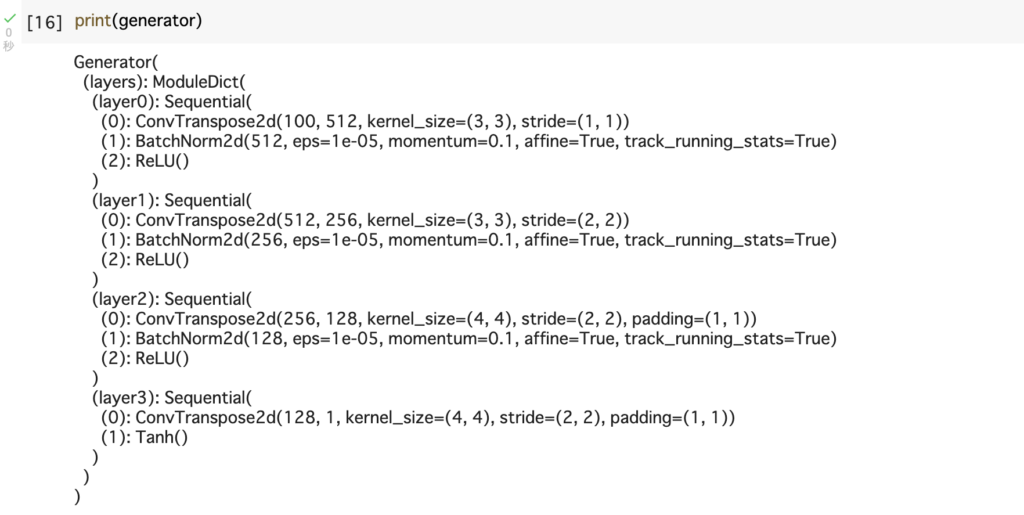
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.layers = nn.ModuleDict({
'layer0': nn.Sequential(
nn.ConvTranspose2d(n_channel, 512, 3, 1, 0),
nn.BatchNorm2d(512),
nn.ReLU()
),
'layer1': nn.Sequential(
nn.ConvTranspose2d(512, 256, 3, 2, 0),
nn.BatchNorm2d(256),
nn.ReLU()
),
'layer2': nn.Sequential(
nn.ConvTranspose2d(256, 128, 4, 2, 1),
nn.BatchNorm2d(128),
nn.ReLU()
),
'layer3': nn.Sequential(
nn.ConvTranspose2d(128, 1, 4, 2, 1),
nn.Tanh()
)
})
def forward(self, z):
for layer in self.layers.values():
z = layer(z)
return z
# [13]
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.layers = nn.ModuleDict({
'layer0': nn.Sequential(
nn.Conv2d(1, 128, 4, 2, 1),
nn.LeakyReLU(negative_slope=0.2)
),
'layer1': nn.Sequential(
nn.Conv2d(128, 256, 4, 2, 1),
nn.BatchNorm2d(256),
nn.LeakyReLU(negative_slope=0.2)
),
'layer2': nn.Sequential(
nn.Conv2d(256, 512, 3, 2, 0),
nn.BatchNorm2d(512),
nn.LeakyReLU(negative_slope=0.2)
),
'layer3': nn.Sequential(
nn.Conv2d(512, 1, 3, 1, 0),
nn.Sigmoid()
)
})
def forward(self, x):
for layer in self.layers.values():
x = layer(x)
return x.squeeze()
# [14]
generator = Generator().to(device)
discriminator = Discriminator().to(device)
# [15]
criterion = nn.BCELoss()
optimizerG = optim.Adam(generator.parameters(), lr = 0.0002, betas=(0.5, 0.999), weight_decay=1e-5)
optimizerD = optim.Adam(discriminator.parameters(), lr = 0.0002, betas=(0.5, 0.999), weight_decay=1e-5)
# [16]
print(generator)
# [17]
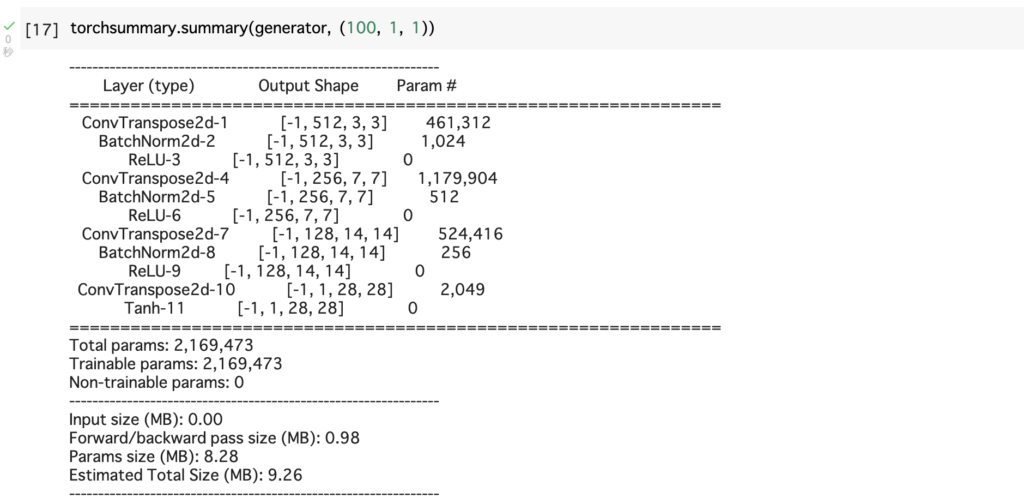
torchsummary.summary(generator, (100, 1, 1))
# [18]
print(discriminator)
# [19]
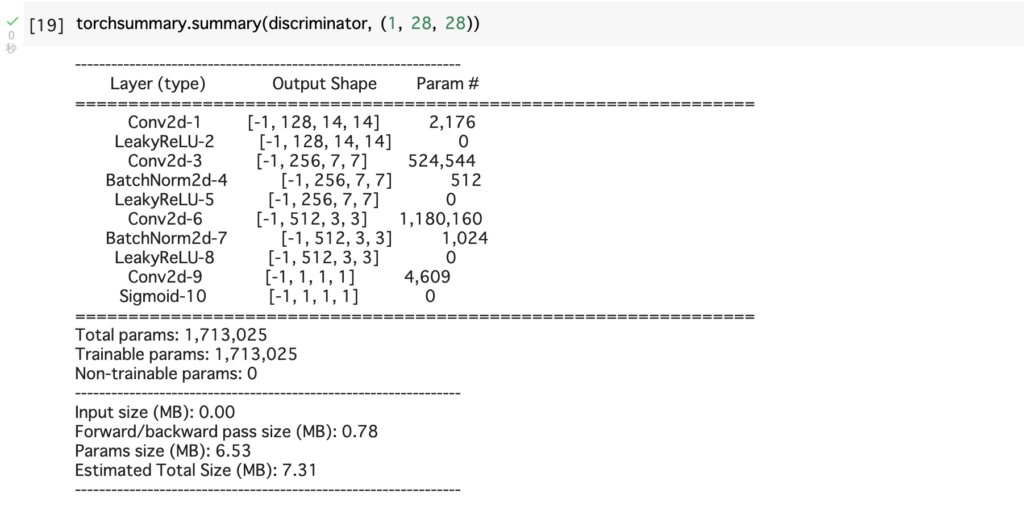
torchsummary.summary(discriminator, (1, 28, 28))
4 モデルの学習
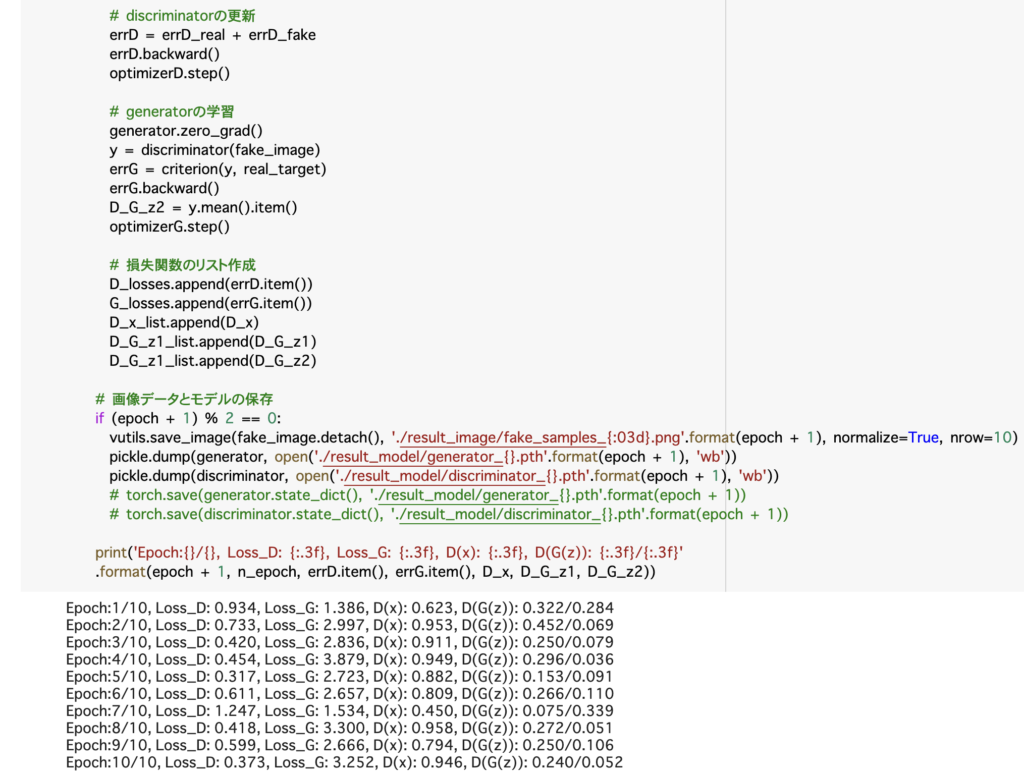
# [20]
pre = 0
# []
generator = pickle.load(open('./result_model/generator_{}.pth'.format(pre), 'rb'))
discriminator = pickle.load(open('./result_model/discriminator_{}.pth'.format(pre), 'rb'))
# generator.load_state_dict(torch.load('./result_model/generator_{}.pth'.format(pre)))
# discriminator.load_state_dict(torch.load('./result_model/discriminator_{}.pth'.format(pre)))
# [21]
G_losses = []
D_losses = []
D_x_list = []
D_G_z1_list = []
D_G_z2_list = []
# 学習のループ
for epoch in range(pre, n_epoch):
for x in dataloader:
# 前準備
real_image = x.to(device) # 本物の画像データ
noise = torch.randn(batch_size, n_channel, 1, 1, device=device) # ノイズ作成
real_target = torch.full((batch_size,), 1., device=device) # 本物ラベル
fake_target = torch.full((batch_size,), 0., device=device) # 偽物ラベル
# discriminatorの学習(本物画像の学習)
discriminator.zero_grad()
y = discriminator(real_image)
errD_real = criterion(y, real_target)
D_x = y.mean().item()
# discriminatorの学習(偽物画像の学習)
fake_image = generator(noise)
y = discriminator(fake_image.detach())
errD_fake = criterion(y, fake_target)
D_G_z1 = y.mean().item()
# discriminatorの更新
errD = errD_real + errD_fake
errD.backward()
optimizerD.step()
# generatorの学習
generator.zero_grad()
y = discriminator(fake_image)
errG = criterion(y, real_target)
errG.backward()
D_G_z2 = y.mean().item()
optimizerG.step()
# 損失関数のリスト作成
D_losses.append(errD.item())
G_losses.append(errG.item())
D_x_list.append(D_x)
D_G_z1_list.append(D_G_z1)
D_G_z1_list.append(D_G_z2)
# 画像データとモデルの保存
if (epoch + 1) % 2 == 0:
vutils.save_image(fake_image.detach(), './result_image/fake_samples_{:03d}.png'.format(epoch + 1), normalize=True, nrow=10)
pickle.dump(generator, open('./result_model/generator_{}.pth'.format(epoch + 1), 'wb'))
pickle.dump(discriminator, open('./result_model/discriminator_{}.pth'.format(epoch + 1), 'wb'))
# torch.save(generator.state_dict(), './result_model/generator_{}.pth'.format(epoch + 1))
# torch.save(discriminator.state_dict(), './result_model/discriminator_{}.pth'.format(epoch + 1))
print('Epoch:{}/{}, Loss_D: {:.3f}, Loss_G: {:.3f}, D(x): {:.3f}, D(G(z)): {:.3f}/{:.3f}'
.format(epoch + 1, n_epoch, errD.item(), errG.item(), D_x, D_G_z1, D_G_z2))
5 画像の生成


# [22]
# fake_image作成
generator.eval
noise = torch.randn(50, n_channel, 1, 1, device=device)
sample_images = generator(noise)
# fake_image可視化
fig = plt.figure(figsize=(20,20))
plt.subplots_adjust(wspace=0.1, hspace=-0.8)
for i in range(50):
ax = fig.add_subplot(5, 10, i+1, xticks=[], yticks=[])
ax.imshow(sample_images[i,].view(28,28).cpu().detach(), "gray")



