【Rで多変量解析#4】判別分析(マハラノビスの距離)
記事の目的
判別分析をRを使用して実装していきます。データの作成から実装するので、コピペで再現することが可能です。
目次
1 ライブラリ
library(dplyr) library(ggplot2) library(MASS)
2 単変量の場合
2.1 データ
set.seed(1)
売り上げ <- c(rnorm(100, 2000, 70), rnorm(100, 1700, 70)) %>% round(1)
顧客 <- c(rep("顧客", 100), rep("退会", 100))
data <- data.frame(売り上げ, 顧客)
data %>% head()

2.2 データの可視化
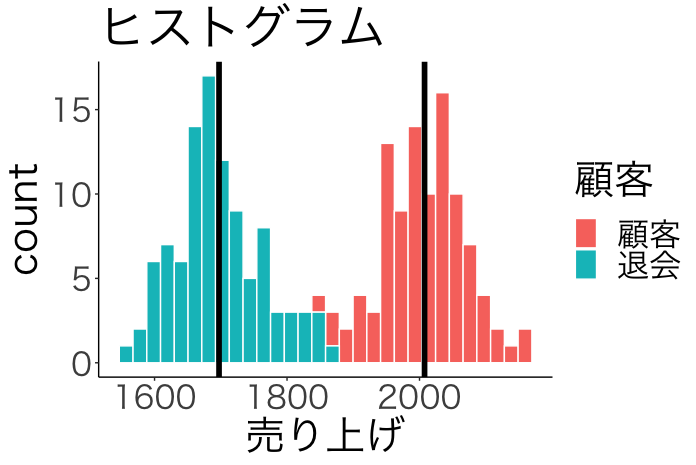
data %>% ggplot(aes(売り上げ, fill=顧客))+ geom_histogram(col="white")+ theme_classic(base_family = "HiraKakuPro-W3")+ theme(text=element_text(size=30)) + labs(title="ヒストグラム")+ scale_x_continuous(breaks=seq(1600,2100, 200))+ geom_vline(xintercept = mean(filter(data, 顧客=="退会")$売り上げ), size=2) + geom_vline(xintercept = mean(filter(data, 顧客=="顧客")$売り上げ), size=2)
2.3 判別分析
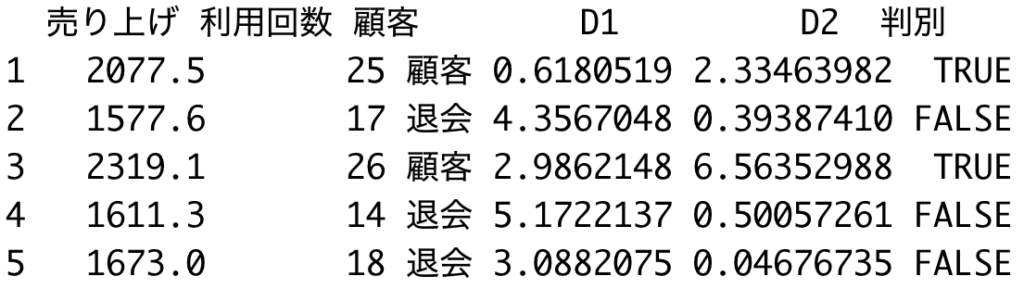
data1 <- filter(data, 顧客=="顧客")$売り上げ data2 <- filter(data, 顧客=="退会")$売り上げ D1 <- (data$売り上げ - mean(data1))^2/var(data$売り上げ) D2 <- (data$売り上げ - mean(data2))^2/var(data$売り上げ) data$D1 <- D1 data$D2 <- D2 data$判別 <- D1 < D2 data %>% sample_n(5)
3 多変量の場合
3.1 データ
set.seed(1)
売り上げ <- c(rnorm(50, 2000, 200), rnorm(50, 1700, 200)) %>% round(1)
利用回数 <- c(rpois(50, 30), rpois(50, 20))
顧客 <- c(rep("顧客", 50), rep("退会", 50))
data <- data.frame(売り上げ, 利用回数, 顧客)
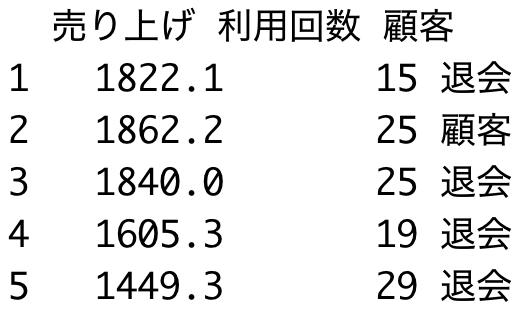
data %>% sample_n(5)
3.2 データの可視化
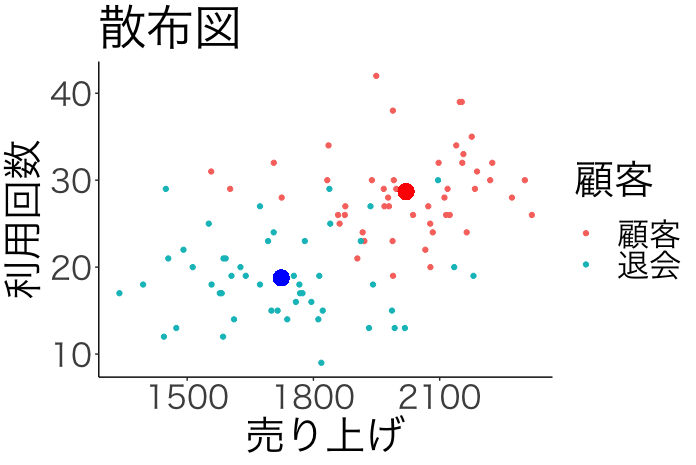
data %>% ggplot()+ geom_point(aes(売り上げ, 利用回数, col=顧客))+ geom_point(aes(mean(filter(data,顧客=="顧客")$売り上げ), mean(filter(data,顧客=="顧客")$利用回数)), col="red", size=5)+ geom_point(aes(mean(filter(data,顧客=="退会")$売り上げ), mean(filter(data,顧客=="退会")$利用回数)), col="blue", size=5)+ theme_classic(base_family = "HiraKakuPro-W3")+ theme(text=element_text(size=30)) + labs(title="散布図")
3.3 判別分析
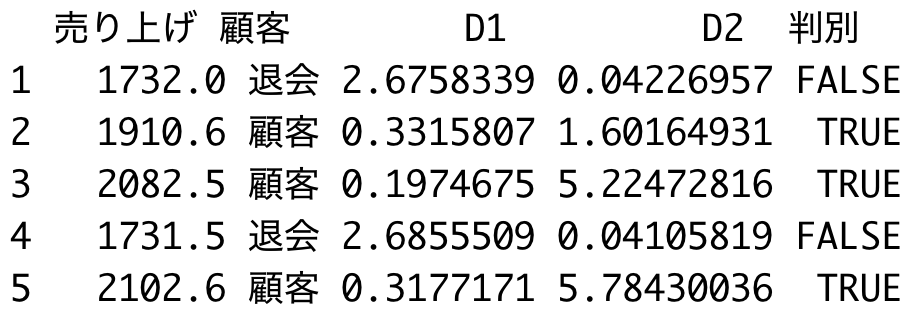
X <- data[,c(1,2)] mu1 <- apply(filter(data[,c(1,2)], 顧客=="顧客"), 2, mean) mu2 <- apply(filter(data[,c(1,2)], 顧客=="退会"), 2, mean) V <- cov(X) D1 <- t(t(X)-mu1) %*% solve(V) %*% (t(X)-mu1) D2 <- t(t(X)-mu2) %*% solve(V) %*% (t(X)-mu2) D1 <- mahalanobis(X,mu1,V) D2 <- mahalanobis(X,mu2,V) data$D1 <- D1 data$D2 <- D2 data$判別 <- D1 < D2 data %>% sample_n(5)