【R言語の基礎#3】データの整理(dplyr)
記事の目的
R言語のライブラリdplyrの基本的な使い方について解説します。主にデータ整理のために使われ、データの前処理に使用するととても便利です。
目次
1 使用するライブラリとデータの作成
1.1 使用するライブラリ
dplyrというライブラリを使用します。
install.packages("dplyr") # 一度もインストールしていない場合
library(dplyr)
1.2 データの作成
以下のように、rnorm()で正規分布から乱数を発生させたり、rbinom()で二項分布から乱数を発生させてデータを作成します。ただ、今回のrbinom()はベルヌーイ分布を表して、0,1のデータを出力します。
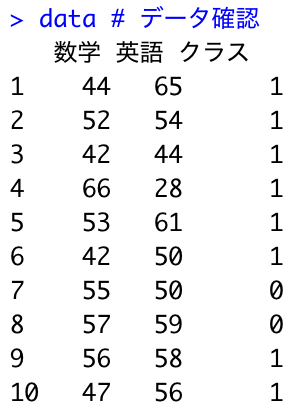
set.seed(1) 数学 <- round(rnorm(10, 50, 10)) # 数学~N(50,10) 英語 <- round(rnorm(10, 50, 10)) # 英語~N(50,10) クラス <- rbinom(10, 1, 0.5) # クラス~B(1,0.5), クラス~Be(0.5) data <- data.frame(数学, 英語, クラス) # データフレーム作成 data # データ確認
2 データの確認
2.1 上からいくつか確認
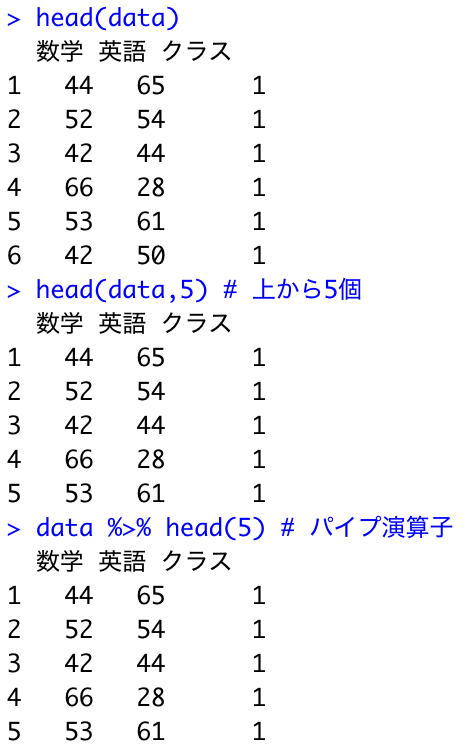
パイプ演算子を使用することで、関数を逐次的に使用できます。
%>% head()でhead()関数を適応します。
head(data) head(data,5) # 上から5個 data %>% head(5) # パイプ演算子
2.2 ランダムにいくつか確認
sample_n()はランダムにデータを指定した分表示します。
data %>% sample_n(5) # ランダムに5個

3 パイプ演算子の利用
3.1 select (カラム選択)
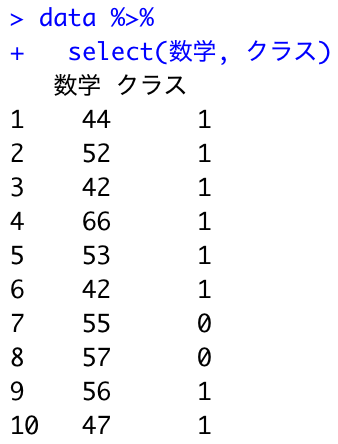
select()で列名を指定して指定した列のデータを取得できます。
data %>% select(数学, クラス) # カラム選択
3.2 filter (条件の合う行を選択)
filter()で条件に適したデータを指定することができます。
data %>% select(数学, クラス) %>% # カラム選択 filter(数学>50) # 条件

3.3 mutate (既存データの変更や追加)
mutate()で新しい列を追加りたり、既存データの変更することができます。
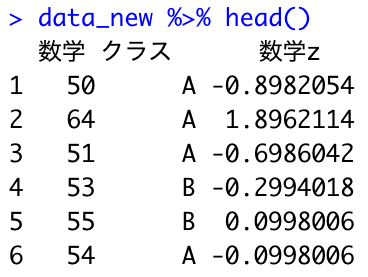
data %>% select(数学, クラス) %>% # カラム選択 filter(数学>50) %>% # 条件 mutate(数学z=scale(数学)) %>% # 新しい列追加 mutate(数学=数学-2) %>% # 既存データの変更 mutate(クラス=ifelse(クラス==1, "A", "B")) # ifelse(条件, TRUE, FALSE)

3.4 arrange(データを昇順や降順に並び替える)
arrange()でデータを昇順や降順に並び替えることができます。
data %>% select(数学, クラス) %>% # カラム選択 filter(数学>50) %>% # 条件 mutate(数学z=scale(数学)) %>% # 新しい列追加 mutate(数学=数学-2) %>% # 既存データの変更 mutate(クラス=ifelse(クラス==1, "A", "B")) %>% # ifelse(条件, TRUE, FALSE) arrange(数学) %>% # 昇順 arrange(desc(数学)) # 降順

3.5 rename (カラム名変更)
rename()でカラム名を変更することができます。
data %>% select(数学, クラス) %>% # カラム選択 filter(数学>50) %>% # 条件 mutate(数学z=scale(数学)) %>% # 新しい列追加 mutate(数学=数学-2) %>% # 既存データの変更 mutate(クラス=ifelse(クラス==1, "A", "B")) %>% # ifelse(条件, TRUE, FALSE) arrange(数学) %>% # 昇順 arrange(desc(数学)) %>% # 降順 rename(英語=数学) # カラム名変更

3.6 group_by + summarise (グループごとの集計)
グループごとの集計方法です。
data %>% select(数学, クラス) %>% # カラム選択 filter(数学>50) %>% # 条件 mutate(数学z=scale(数学)) %>% # 新しい列追加 mutate(数学=数学-2) %>% # 既存データの変更 mutate(クラス=ifelse(クラス==1, "A", "B")) %>% # ifelse(条件, TRUE, FALSE) arrange(数学) %>% # 昇順 arrange(desc(数学)) %>% # 降順 rename(英語=数学) %>% # カラム名変更 group_by(クラス) %>% # グループ分け summarise(英語m=mean(英語), 英語s=sum(英語)) # 集計

4 データの格納
data_new <- data %>% select(数学, クラス) %>% # カラム選択 filter(数学>50) %>% # 条件 mutate(数学z=scale(数学)) %>% # 新しい列追加 mutate(数学=数学-2) %>% # 既存データの変更 mutate(クラス=ifelse(クラス==1, "A", "B")) # ifelse(条件, TRUE, FALSE) data_new %>% head()